






Hotel Ratings Classification: Project Overview
- Created a tool that predicts rating, a customer will give based on reviews provided by them.
- Done text pre-processing on over 20,000 reviews to prepare the data that can be used for further research.
- Applied different NLP techniques like Named Entity Recognition(NER), Topic Modeling, Sentiment Analysis, N-grams and Word clouds to extract information.
- Used TF-IDF as input feature, and optimized Multinomial Logistic Regression with different solvers to reach the best model.
- Built a client facing Web app deployed on Heroku.
- More information on this project can be found in PPT (click here).
Deployment Link: https://hotel–rating-prediction.herokuapp.com/
Demo :
Code and Resources Used
Python Version: 3.7
Packages: pandas, numpy, sklearn, matplotlib, seaborn, nltk, spacy, gensim, wordcloud, flask, pickle
For Web Framework Requirements: pip install -r requirements.txt
Business Problem/Obejctive:
A sample dataset which consists of 20,000 reviews and ratings for different hotels and goal is to examine how travellers are communicating their positive and negative experiences in online platforms for staying in a specific hotel and major objective is what are the attributes that travellers are considering while selecting a hotel. With this manager can understand which elements of their hotel influence more in forming a positive review or improves hotel brand image.
Project Architecture / Flow
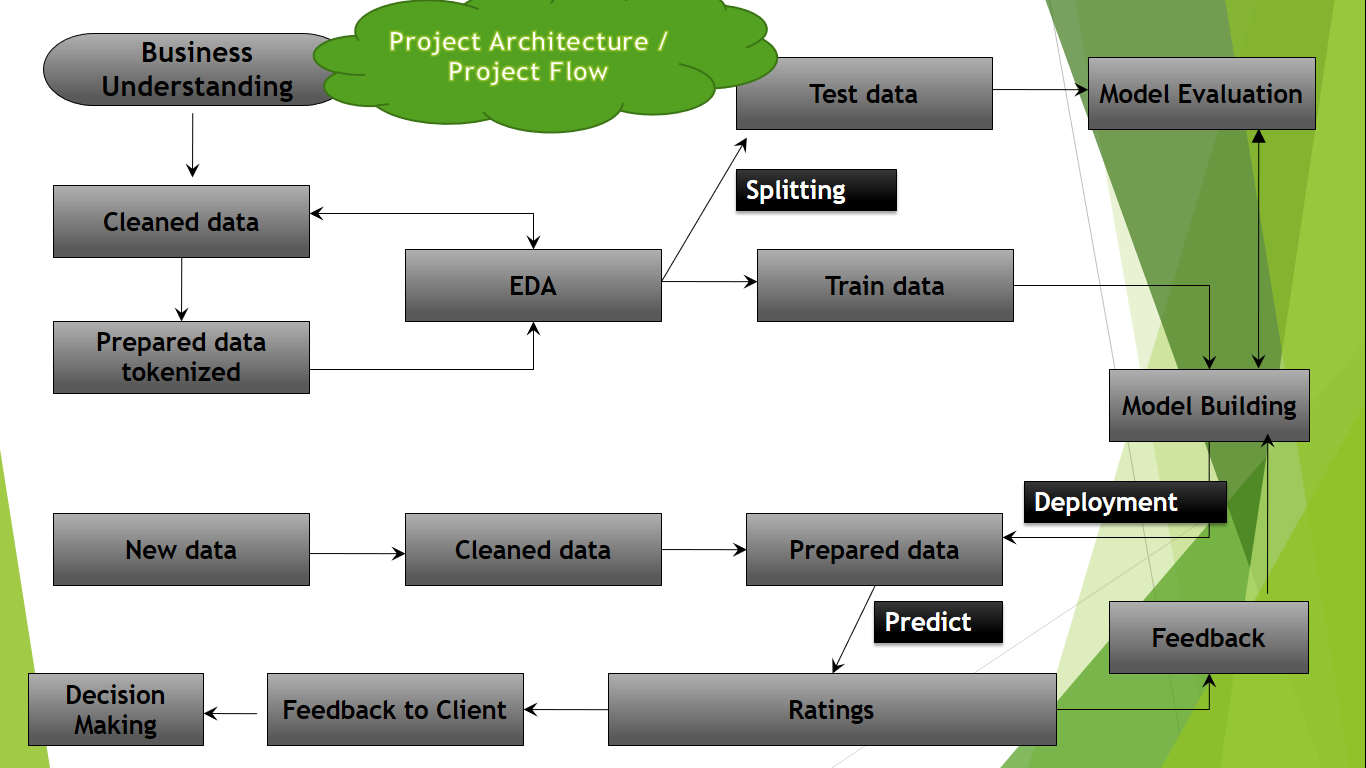
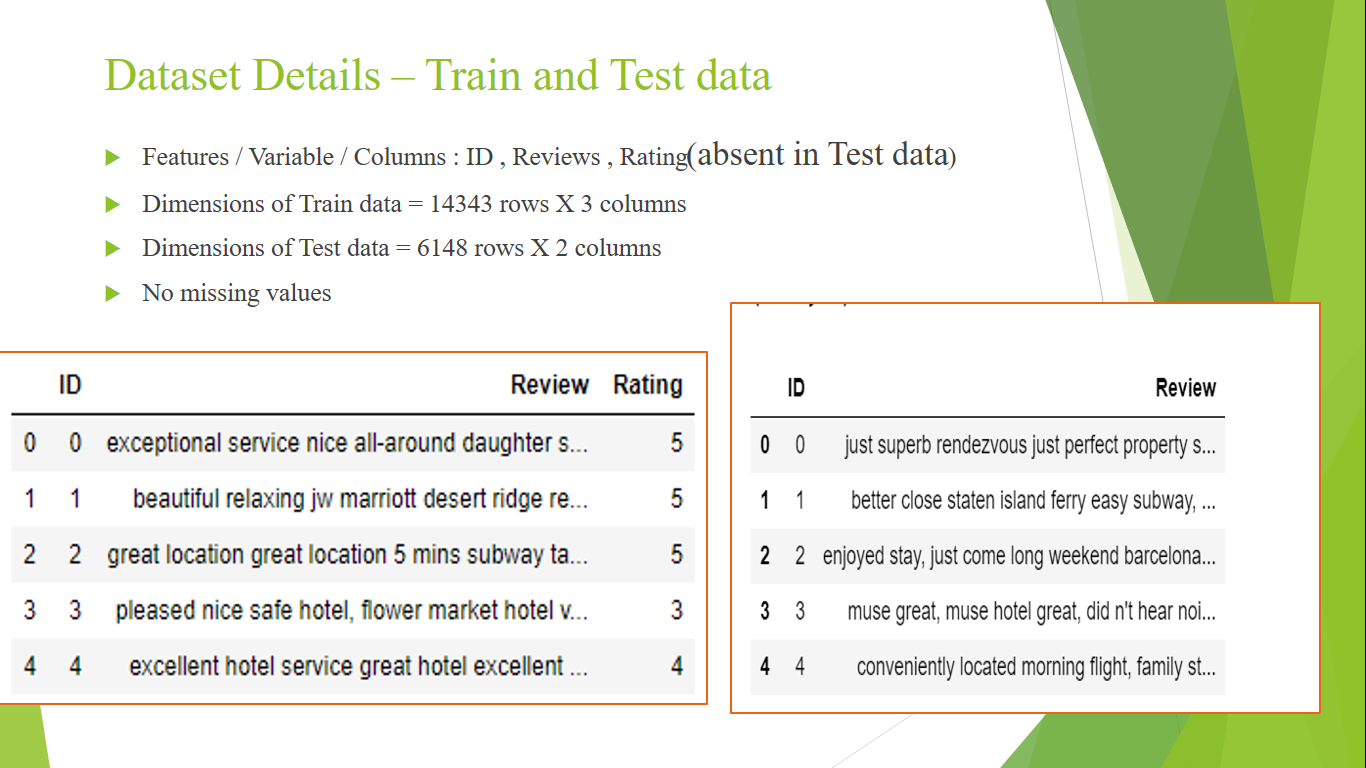
Dataset Details:
- Dataset was provided by creating in-house competition group in Kaggle.
- Dataset was pre-splitted into Train and Test data.
Exploratory Data Analysis (EDA):
This is the most crucial part of any Data Science project. I adopted following EDA steps for this NLP project:
1. Text pre-processing:
Following text pre-processing steps were included:
- Converted to lower case, removed stop words by creating some new custom stop words.
- Removed punctuations, tags, special characters and digits, Lemmatization – reduced words to their root words.
- Combined the rating level : Instead of using 5 level rating used 3 level because prediction for 5 level was very poor.
2. N-gram Analysis:
- Created Uni-gram, Bi-gram and tri-gram to find out pair of words used in different rating levels.
3. Word Clouds
- Created an overall word cloud. Also created positive word cloud and negative word cloud to find out positive and negative words respectively.
4. Sentimental Analysis:
- Done sentiment analysis using VADER. Found out most positive reviews and most negative reviews based on obtained compound scores.
5. Named Entity Recognition (NER):
- Implemented NER or Entity extraction. It is a popular technique used in information extraction to identify and segment the named entities and classify or categorize them under various predefined classes
6. Topic Modeling:
- Used classical approach of LDA model to create 4 topics that can be clearly distinguished and named.
Model Building:
- Used different input features like Bag of words, Term Frequency(TF), Term Frequency - Inverse Document Frequency(TF-IDF).
- Used various model with changed attributes and parameters like Multinomial logistic regression, SVM, KNN, Naive Bayes, Neural Network, Decision Tree, Random Forest.
- Handled imbalanced dataset using SMOTE but results were poor, 3 level rating gave more satisfied results than 5 level of ratings.
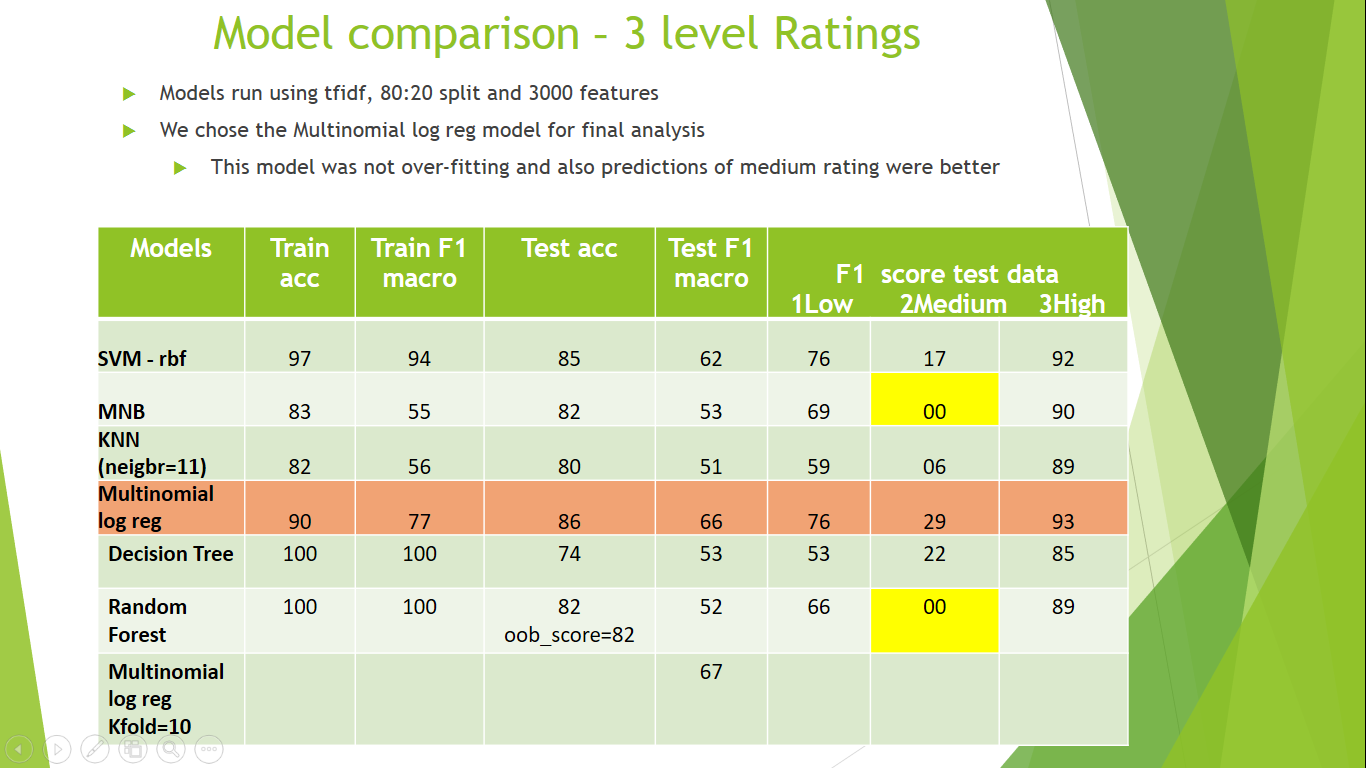
Model Evaluation
-
All the models were evaluated based on F1 score on validation dataset.
-
Multinomial Logistic Regression outperformed the other approaches on the validation dataset.
-
Test dataset was similarily processed and done predictions which were submitted in Kaggle.
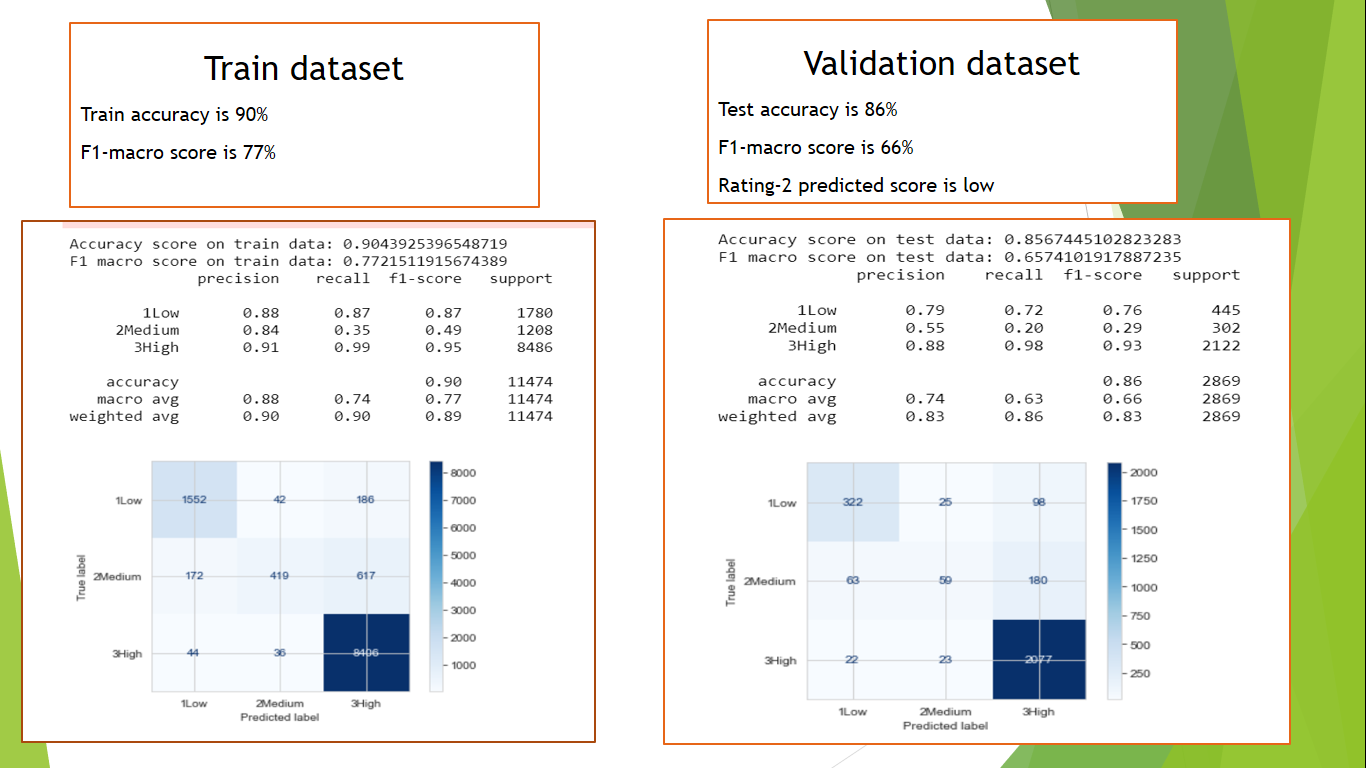
Challenges Faced:
-
Though the initial rating level was 5, it gave poor results especially for ratings 2,3,4. Hence combined the ratings to 3 levels. This performed better.
-
Ran innumerable models by changing various attributes and parameters, Advanced models were more subjective and hence gave low result scores, But the basic multinomial logistic gave better results, hence it was chosen.
-
Many words like ‘aaa’, ‘abc’ appeared with moderate frequency.Hence they were checked with original reviews. But were found genuine like former was aaa- rating and latter was abc-store. Other words which were meaningless were removed.
-
The dataset had about 14000 reviews, which is small considering that we have to do text classification. Also the data is imbalanced.